

打印PDF
近日,数智化建设处魏子涵老师设计了一种细粒度偏好优化算法,有效解决了大模型推荐中生成token权重无区分度的问题。相关工作以《Fine-Grained Preference Optimization with Differentiated Token Weighting for LLM-based Recommendations》为题发表在《Knowledge-Based Systems》(中科院SCI期刊计算机科学1区TOP;影响因子:7.6)上。
该研究提出细粒度偏好优化(FGPO),通过轻量级多层感知机(MLP)构建差异化token加权机制,根据token对用户偏好的贡献度分配不同权重,并结合可调超参数平衡正负样本信号。此外,提出多负样本扩展策略,通过增强对比学习信号提升模型区分能力。FGPO被实例化为两种优化方法——细粒度直接偏好优化(FGDPO)和细粒度简单偏好优化(FGSimPO)。在三个真实公开数据集上的实验表明,两者均显著提升了LLM推荐系统的效用。
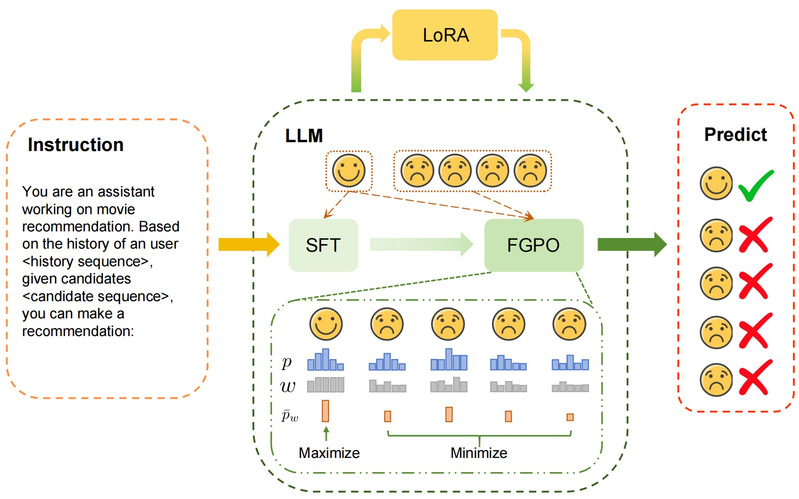
FGPO整体框架图
近年来,数智化建设处高度重视高水平科学研究,以教育数字化转型为契机,以开放教育教学平台建设为支撑,以科研赋能教育,在相关领域取得了一系列科研成果,为全面落实高质量推进开放大学数智化建设贡献应有之义。
论文链接:https://doi.org/10.1016/j.knosys.2025.114805
(文/图:魏子涵 审核:姜春艳)
上一篇:下一篇:
